Natural Language Processing (NLP) MSc IT - Sem IV - As per Mumbai University Syllabus

Unit - 1
Chapter: 1Introduction to NLP, Brief history, NLP applications: Speech To Text (STT) / Speech Recognition, Text to Speech (TTS), Story Understanding, NL Generation /Conversation systems – Dialog Systems / Chatbots, QA system, Machine Translation / Language Translation, challenges/Open Problems, NLP abstraction levels, Natural Language (NL) Characteristics, NL computing approaches / techniques and steps.NL tasks: Segmentation, Chunking, tagging, NER (Named Entity Recognition), Parsing, Word Sense Disambiguation, NL Generation,Web 2.0 Applications : Sentiment Analysis, Text Entailment, Cross Lingual Information Retrieval (CLIR)Chapter: 2Text PreprocessingIntroduction, Challenges of Text Pre-processing, Word Level -Tokenization, Sentence Segmentation






Let us now focus on the specific technical issues that arise in tokenization.Many factors can affect the difficulty of tokenizing a particular natural language.One fundamental difference exists between tokenization approaches for space-delimited languages and approaches for unsegmented languages.
The tokenization of unsegmented languages therefore requires additional lexical and morphological (structural) information.

a) Tokenizing Punctuation

Common Approaches:




Finite State Morphonology





Two level morphology


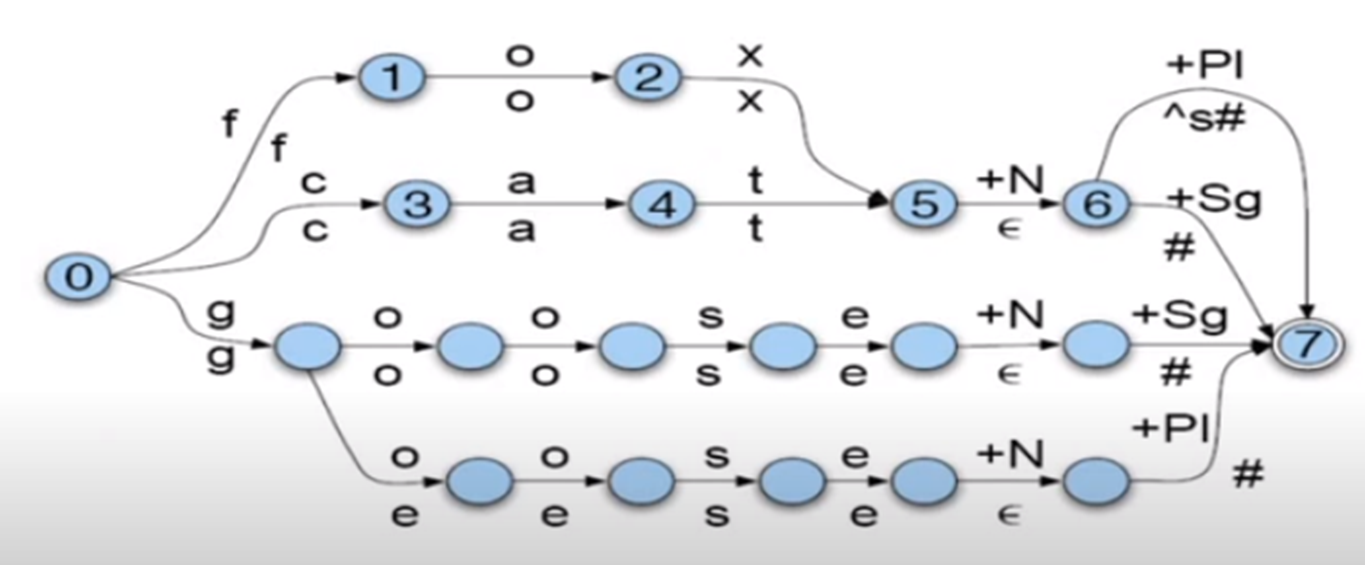









Unit – 2
Syntactic Parsing :Introduction, Background, Parsing as Deduction, Implementing Deductive Parsing, LR Parsing, Issues in Parsing, Parsing as Deduction, Implementing Deductive Parsing, LR Parsing, Issues in Parsing
Semantic analysis, Basic Concepts and Issues in Natural Language Semantics, Theories and Approaches to Semantic Representation, Theories and Approaches to Semantic Representation, Relational Issues in Lexical Semantics, Relational Issues in Lexical Semantics, Fine-Grained Lexical-Semantic Analysis - Functional Macro Categories (A case study)
Natural Language Generation, Approaches to Text Planning, The Linguistic Component, The Cutting Edge
Introduction
This chapter presents basic techniques for grammar-driven natural language parsing, that is, analysing a string of words (typically a sentence) to determine its structural description according to a formal grammar.
Computer languages are usually designed to permit encoding by unambiguous grammars and parsing in linear time of the length of the input.
To this end, the subclasses of context-free grammar (CFG) are used.
One of the strongest cases for expressive power has been the occurrence of long-distance dependencies, as in English wh-questions:
Who did you sell the car to __? (4.1)
Who do you think that you sold the car to __? (4.2)
Who do you think that he suspects that you sold the car to __? (4.3)
There is no clear limit as to how much material may be embedded between the two ends, as suggested by (4.2) and (4.3), linguists generally take the position that these dependencies might hold at unbounded distance.
Hence, we require some logic beyond context-free power.
A second difference concerns the extreme structural ambiguity of natural language.
A classic example is the following:
Put the block in the box on the table__________ (4.4)
“put” subcategorizes for two objects, there are two possible analyses of (4.4):
Put the block [in the box on the table]________________ (4.5)
Put [the block in the box] on the table________________ (4.6)
If we add another prepositional phrase (“in the kitchen”), we get some more analyses; if we add yet another, we get still some more, and so on.
Constructions of this kind have a number of analyses that grows exponentially with the number of added components.
A third difference is that natural language data are inherently noisy, both because of errors and because of the ever persisting incompleteness of lexicon and grammar which constitute the language.
In contrast, a computer language has a complete syntax specification, which means that by definition all correct input strings are parsable.
Input containing errors may still carry useful bits of information that might be desirable to try to recover.
Robustness refers to the ability of always producing some result in response to such input
Background
Context-Free Grammars:
It is introduced by Chomsky (1956).
CFG has been the most influential grammar formalism for describing language syntax.
The standard way of defining a CFG is as a tuple G = (Σ, N, S, R), where Σ and N are disjoint finite sets of terminal and nonterminal symbols, respectively, and S ∈ N is the start symbol.
The nonterminals are also called categories, and the set V = N ∪ Σ contains the symbols of the grammar.
R is a finite set of production rules of the form A → α, where A ∈ N and α ∈ V∗.
We use capital letters A, B, C, . . . for nonterminals, lower-case letters s, t, w, . . . for terminal symbols, and uppercase X, Y, Z, . . . for general symbols (elements in V).
Greek letters α, β, γ , . . . will be used for sequences of symbols, and we write for the empty sequence.
A phrase is a sequence of terminals.
The sequence of rule expansions is called a derivation of B from A.
A (grammatical) sentence is a phrase that can be derived from the start symbol S.
The string language L(G) accepted by G is the set of sentences of G.
The grammar is shown in Figure 4.1.
Example Grammar
Syntax Trees
The standard way to represent the syntactic structure of a grammatical sentence is as a syntax tree, or a parse tree, which is a representation of all the steps in the derivation of the sentence from the root node.
This means that each internal node in the tree represents an application of a grammar rule.
Note that the tree is drawn upside-down, with the root of the tree at the top and the leaves at the bottom.
Another representation, which is commonly used in running text, is as a bracketed sentence, where the brackets are labeled with nonterminals:
[S [NP [Det the ] [NBar [Adj old ] ] ] [VP [Verb man ] [NP [Det a ] [NBar [Noun ship ] ] ] ] ]
Example of CFG in Compiler
Let we have a tuple G = (Σ, N, S, R) where Σ is terminal (leaf nodes) , N is nonterminal (interior nodes), S is start symbol and R is production rules.
Consider R is given as:
S -> E (read as: S produces E)
E -> E + E \ E * E \a \b \c with input a+b*c.
Then draw the syntax tree.
On this sile, the right most derivation is sown; because right terminal is elaborated. You can design left most derivation also in the same way.

Example of CFG in NLP
Given I/P : The little boy ran quickly.
Grammar:
<sentence> -> <NP><VP>
<NP> -> <Adj><NP> and <Adj> <Singular Noun>
<VP> -> <Singular Verb><Adverb>
<Adj> -> a / the / little
<Singular Noun> -> boy
<Singular Verb> -> ran
<Adverb> -> quickly
Then draw the syntax tree.
Other Grammar Formalisms
In practice, pure CFG is not widely used for developing natural language grammars
One reason for this is that CFG is not expressive enough—it cannot describe all peculiarities (uniqueness) of natural language,
Also, it is difficult to use; e.g., agreement, inflection, and other common phenomena are complicated to describe using CFG.
There are also several grammar formalisms (e.g., categorial grammar, TAG, dependency grammar) that may or may not been designed as extensions of CFG.
Types of Grammars:
1. Mildly Context-Sensitive Grammars:
A grammar formalism is regarded as mildly context-sensitive (MCS) if it can express some linguistically motivated non-context-free constructs (multiple agreement, crossed agreement, and duplication), and can be parsed in polynomial time with respect to the length of the input.
2. Constraint-Based Grammars:
A key characteristic of constraint-based grammars is the use of feature terms (sets of attribute–value pairs) for the description of linguistic units.
3. Dependency Grammars:
The structure consists of lexical elements linked by binary dependency relations.
A dependency structure is a directed acyclic graph between the words in the surface sentence, where the edges are labeled with syntactic functions (such as SUBJ, OBJ etc).
Basic Concepts in Parsing:
A recognizer is a procedure that determines whether or not an input sentence is grammatical according to the grammar and also including the lexicon – word.
A parser is a recognizer that produces associated structural analyses according to the grammar.
A robust parser attempts to produce useful output, such as a partial analysis, even if the input is not covered by the grammar.
A sequence that connects the state S, the string consisting of just the start category of the grammar, and a state consisting of exactly the string of input words, is called a derivation.
Parsers can be classified along several dimensions according to the ways in which they carry out derivations.
One such dimension concerns rule invocation: In a top-down derivation, each sentential form is produced from its predecessor by replacing one nonterminal symbol A by a string of terminal or nonterminal symbols.
Conversely, in a bottom-up derivation each sentential form is produced by successively applying rules in the reverse direction.
Another dimension concerns the way in which the parser deals with ambiguity, in particular, whether the process is deterministic or nondeterministic.
Example
The following sentence and the grammar given. Apply top down and bottom up approaches to solve it.
I/P :- Book that flight
S -> VP
VP -> VP NP
NP -> Det NP
Det -> that
NP -> singular Noun
singular Noun -> flight
Verb -> book
Parsing as Deduction
It is a deductive process in which rules of inference are used to derive statements about the grammatical status of strings from other such statements
The inference rules are written in natural deduction style. e.g., grammar rules.
The statements in a deduction system are called items, and are represented by formulae in some formal language.
The set of items built in the deductive process is sometimes called a chart or chart parsing.
Top down and bottom up parsing are the examples of parsing.
Implementing Deductive Parsing 1 Agenda-Driven Chart Parsing 2. Storing and Retrieving Parse Results
1 Agenda-Driven Chart Parsing:
A chart can be calculated using a forward-chaining deduction procedure.
Whenever an item is added to the chart, its consequences are calculated and added.
However, since one item can give rise to several new items, we need to keep track of the items that are waiting to be processed.
The idea is as follows:
First, we add all possible consequences of the axioms to the agenda.
Then we remove one item e from the agenda, add it to the chart, and add all possible inferences that are trigged by e to the agenda.
This second step is repeated until the agenda is empty
2. Storing and Retrieving Parse Results:
The set of parse trees for a given string is called a parse forest.
The size of this set can be exponential in the length of the string. For example, for NP, S -> VP, VP -> VP NP, NP -> Det NP, NP -> singular Noun
A parse forest can be represented as a CFG, recognizing the language consisting of only the input string.
From a parse forest, it is possible to produce a single parse tree in time linear to the size of the forest, and it is possible to iterate through all possible parse.
So, if you either consider that "build a parse tree" means "find one of the possible parses" or if you consider that it means "build a data structure which represents all possible parses", then you can certainly do that with a CYK grammar in O(n3).
If, on the other hand, you intend "build a parse tree" to mean "build all parse trees for a sentence", then it is not limited to exponential time; it is easy to write a grammar with an infinite number of possible parses for certain sentences.
LR Parsing (LR -> Left to right, merging common subpart of Right)
Instead of using the grammar directly, we can precompile it into a form that makes parsing more efficient.
One of the most common strategies is LR parsing, It is mostly used for deterministic parsing of formal languages such as programming languages, but was extended to nondeterministic languages
One of the main ideas of LR parsing is to handle a number of grammar rules simultaneously by merging common subparts of their right-hand sides, rather than attempting one rule at a time.
An LR parser compiles the grammar into a finite automaton, augmented with reductions for capturing the nesting of nonterminals in a syntactic structure, making it a kind of push-down automaton (PDA).
The automaton is called an LR automaton, or an LR table.
LR automata can be constructed in several different ways.
The simplest construction is the LR(0) table, where (0) indicates bottom-up approach. The LR(0) table uses no lookahead when it constructs its states.
States
The states in an LR table are sets of dotted rules A → α•β.
To build an LR(0) table we do the following. First, we have to define the function PREDICT-CLOSURE(q).
Transitions
Transitions between states are defined by the function GOTO, taking a grammar symbol as argument.
GOTO(q, X) = PREDICT-CLOSURE({A → αX•β | A → α•Xβ ∈ q})
Issues in Parsing
1. Robustness:
Robustness can be seen as the ability to deal with input that somehow does not follow to what is normally expected.
A natural language parser will always be exposed to some amount of input that is not in L(G). 2.
2. Disambiguation:
Although not all information needed for disambiguation may be available during parsing, some pruning of the search space is usually possible and desirable.
The parser may then pass on then best analyses, if not a single one, to the next level of processing.
3. Efficiency:
The worst-case time complexity for parsing with CFG is cubic, O(n^3), in the length of the input sentence.
The main part consists of three nested loops, all ranging over O(n) input positions, giving cubic time complexity.
Basic Concepts and Issues in Natural Language Semantics
Semantic analysis attempts to understand the meaning of Natural Language. Understanding Natural Language might seem a straightforward process to us as humans. However, due to the vast complexity and subjectivity involved in human language, interpreting it is quite a complicated task for machines.
There is a traditional division made between lexical semantics, which concerns itself with the meanings of words and fixed word combinations(e.g. back, ground, background), and supralexical (combinational, or compositional) semantics, which concerns itself with the meanings of the indefinitely large number of word combinations—phrases and sentences—allowable under the grammar.
It is increasingly recognized that word-level semantics and grammatical semantics interact and interpenetrate in various ways.
Many grammatical constructions have construction-specific meanings; for example, the construction to have a VP (to have a drink, a swim, etc.) has meaning components additional to those belonging to the words involved.
A major divide in semantic theory turns on the question of whether it is possible to draw a strict line between semantic content, in the sense of content encoded in the lexicogrammar, and general encyclopaedic knowledge.
One frequently identified requirement for semantic analysis in NLP goes under the heading of ambiguity resolution.
From a machine point of view, many human utterances(e.g. piece and peace) are open to multiple interpretations, because words may have more than one meaning (lexical ambiguity).
In relation to lexical ambiguities, it is usual to distinguish between homonyms (different words with the same form, either in sound or writing, for example, light (vs. dark) and light (vs. heavy), son and sun, and polysemy (different senses of the same word, for example, the several senses of the words hot and see).
Both phenomena are problematical for NLP, but polysemy poses greater problems, because the meaning differences concerned.
Theories and Approaches to Semantic Representation
Various theories and approaches to semantic representation can be roughly ranged along two dimensions:
(1) formal vs. cognitive (logical)
(2) compositional vs. lexical
There are five different approaches to Semantic Representation:
Logical Approaches
Discourse Representation Theory
Pustejovsky’s Generative Lexicon
Natural Semantic Metalanguage
Object-Oriented Semantics
1. Logical Approaches:
Logical approaches to meaning generally address problems in compositionality, on the assumption that the meanings of supralexical (combinational, or compositional) expressions are determined by the meanings of their parts and the way in which those parts are combined.
There is no universal logic that covers all aspects of linguistic meaning and characterizes all valid arguments or relationships between the meanings of linguistic expressions.
The most well known and widespread is predicate logic, in which properties of sets of objects can be expressed via predicates, logical connectives, and quantifiers.
This is done by providing a “syntax” and a “semantics”.
Examples of predicate logic representations are given in (1b) and (2b), which represent the semantic interpretation or meaning of the sentences in (1a) and (2a), respectively.
In these formulae, x is a ‘variable,’ k a ‘term’ (denoting a particular object or entity), politician, mortal, like, etc. are predicates (of different arity),
∧,→are ‘connectives,’ and ∃, ∀ are the existential quantifier and universal quantifier, respectively.
Negation can also be expressed in predicate logic, using the symbol ¬ or a variant.
(1) a. Some politicians are mortal.
b. ∃x (politician(x) ∧ mortal(x))
[There is an x (at least one) so that x is a politician and x is mortal.]
(2) a. All Australian students like Kevin Rudd.
b. ∀x ((student(x) ∧ Australian(x))→like(x, k))
[For all x with x being a student and Australian, x likes Kevin Rudd.]
Notice that, as mentioned, there is no analysis of the meanings of the predicates, which correspond to the lexical items in the original sentences, for example, politician, mortal, student, etc.
Predicate logic also includes a specification of valid conclusions or inferences that can be drawn: a proof theory comprises inference rules whose operation determines which sentences must be true given that some other sentences are true.
The best known example of such an inference rule is the rule of modus ponens: If P is the case and P → Q is the case, then Q is the case:
(3) a. Modus ponens:
(i) P (premise)
(ii) P → Q (premise)
(iii) Q (conclusion)
In the interpretation of sentences in formal semantics, the meaning of a sentence is often equated with its truth conditions, that is, the conditions under which the sentence is true.
This has led to an application of model theory to natural language semantics.
The logical language is interpreted in a way that for the logical statements general truth conditions are formulated, which result in concrete truth values under concrete models (or possible worlds).
2. Discourse Representation Theory (DRT):
The basic idea is that as a discourse or text explains the hearer builds up a mental representation (represented by discourse representation structure, DRS), and that every incoming sentence prompts additions to this representation.
It is thus a dynamic approach to natural language semantics.
A DRS consists of a universe of discourse referents and conditions applying to these discourse referents.
A simple example is given in (4). As (4) shows, a DRS is presented in a graphical format, as a rectangle with two compartments.
The discourse referents are listed in the upper compartment and the conditions are given in the lower compartment. The two discourse referents in the example (x and y) denote a man and he, respectively.
In the example, a man and he are anaphorically linked through the condition y = x, that is, the pronoun he refers back to a man. The linking itself is achieved as part of the construction procedure referred to above.
Recursiveness is an important feature.
DRSs can comprise conditions that contain other DRSs .
An example is given in (5). Notice that according to native speaker intuition this sequence is anomalous (irregular):
though on the face of it every man is a singular noun-phrase, the pronoun he cannot refer back to it.
In the DRT representation, the quantification in the first sentence of (5) results in an if-then condition:
if x is a man, then x sleeps. This condition is expressed through a conditional (A ⇒ B) involving two DRSs. This results in x being declared at a lower level than y, namely, in the nested DRS that is part of the conditional, which means that x is not an accessible discourse referent for y, and hence that every man cannot be an antecedent for he, in correspondence with native speaker intuition.
3. Pustejovsky’s Generative Lexicon
Generative Lexicon (GL) focuses on the distributed nature of compositionality in natural language.
Following are different types of structures by which we can generate/create a statement:
Argument Structure
Event Structure
Qualia Structure
Lexical Inheritance Structure
1. Argument Structure: Describing the logical arguments, and their syntactical realization. Like if cake is made up with sugar then the cake is sweet.
2. Event Structure: defining the event type of the expression and any sub-eventual structure it may have; with subevents; e.g. statement showing some event. E.g. he has completed the assignment.
3. Qualia Structure: a structural differentiation of the predicative(adjective following verb) force for a lexical item. E.g. in the sentence ‘She is happy’ – ‘happy’ is a predicative adjective
4. Lexical Inheritance Structure: Relating one entry in the lexicon to the other entries e.g. we generate the next sentence from the previous sentence, when we talk with someone.
The modes of explanation associated with a word or phrase are defined as follows:
1. formal: the basic category of which distinguishes the meaning of a word within a larger domain; (many people accept it).
2. constitutive(fundamental): the relation between an object and its constituent parts; e.g. happiness. In this word happy is the object.
3. telic: the purpose of the object/word, if there is one directs to a definite end.
4. agentive(producing an effect): the factors involved in the object's origins.
4. Natural Semantic Metalanguage
The Natural semantic metalanguage (NSM) is a linguistic theory that reduces lexicons(wordlist) down to a set of semantic primitives.
Semantic primes/primitives are a set of semantic concepts that are naturally understood but cannot be expressed in simpler terms. They represent words or phrases that are learned through practice but cannot be defined concretely.
For example, although the meaning of "touching" is a link of expression (e.g. your loyalty is very touching), a dictionary might define "touch" as "to make contact (e.g. keep in touch), but touching word doesn’t provide any information..
The NSM system uses a metalanguage, which is essentially a standardized subset of natural language: a small subset of word-meanings explained in Table 5.1.
Table 5.1 is presented in its English version, but comparable tables of semantic primes have been drawn up for many languages, including Russian, French, Spanish, Chinese, Japanese, Korean, and Malay.
5. Object-Oriented Semantics
Object-oriented semantics is a new field in linguistic semantics
In object-oriented semantic approach, the concept of “object” is central, whose characteristics, relates to other entities, behavior, and interactions are modelled.
It uses Unified Entity Representation (UER). It is based on the Unified Modeling Language(UML).
UER diagrams are composed of well-defined graphical modeling elements that represent conceptual categories.
Relational Issues in Lexical Semantics
Linguistic expressions are interrelated in many ways. Following are the relational issues in lexical semantics:
1 Sense Relations and Ontologies
2 Roles
1. Sense(Semantic) Relations and Ontologies
There is a high demand for information on lexical relations and linguistically informed ontologies. Although a rather new field, the interface between ontologies and linguistic structure is becoming a vibrant and influential area in knowledge representation and NLP.
Semantic relations can be both, horizontal and vertical sense relations.
Horizontal relations include synonymy e.g. orange in English is same as Apfelsine in German, incompatible e.g. fin – foot (starting with f but different meaning), antonyms e.g. big-small, complementary e.g. aunt—uncle, converse e.g. above-below and reverse e.g. ascending—descending.
The two principal vertical relations are hyponymy and meronymy.
Hyponymy is when the meaning of one lexical element is more specific than the meaning of the other (e.g., dog—animal). Lexical items that are hyponyms of the same lexical element and belong to the same level in the structure are called co-hyponyms (dog, cat, horse are cohyponyms of animal).
Meronymy is when the meaning of one lexical element specifies that its referent is ‘part of’ the referent of another lexical element, for example, hand—body.
2. Roles:
Roles used to understand situation-specific relations.
Ex: ‘cross a waterbody,’
In semantics, these roles are referred to as semantic roles. Semantic roles are important for the linking of the arguments to their syntactic realizations.
Ex:
Role Description
agent a intentional leader of an action or event
source the point of origin of a state of affairs
Functional Macro-Categories:
In this section, we present three case studies of fine-grained lexical-semantic analysis.
Formal semantics has had little to say about the meanings of emotion words, but words like these are of great importance to social cognition and communication in ordinary language use.
They may be of special importance to NLP applications connected with social networking and with machine–human interaction, but they differ markedly in their semantics from language to language.
Let us see some contrastive examples.
Consider the difference between sad and unhappy.
I miss you a lot at work . . .. I feel so sad (∗unhappy) about what’s happening to you [said to a colleague in hospital who is dying of cancer].
I was feeling unhappy at work [suggests dissatisfaction].
Semantic explication for Someone X felt sad
a. someone X felt something bad
like someone can feel when they think like this:
b. “I know that something bad happened
I don’t want things like this to happen
I can’t think like this: I will do something because of it now
I know that I can’t do anything”
Also, Semantic explication for Someone X felt unhappy
a. someone X felt something bad
like someone can feel when they think like this:
b. “some bad things happened to me
I wanted things like this not to happen to me
I can’t not think about it”
c. this someone felt something like this, because this someone thought like this
Relational Issues in Lexical Semantics
Linguistic expressions are interrelated in many ways. Following are the relational issues in lexical semantics:
1 Sense Relations and Ontologies
2 Roles
1. Sense(Semantic) Relations and Ontologies
Ontology is the branch of philosophy that studies concepts such as existence, being and becoming. It includes the questions of how entities are grouped into basic categories and which of these entities exist on the most fundamental level.
Sense relations can be seen as revelatory of the semantic structure of the lexicon.
There are both horizontal and vertical sense relations.
Horizontal relations include synonymy e.g. orange in English is same as Apfelsine in German, incompatible(mismatch) e.g., fin—foot, antonyms e.g. big-small, complementary e.g. aunt—uncle, converse e.g. above-below and reverse e.g. ascend—descend.
The two principal vertical relations are hyponymy and meronymy.
Hyponymy is when the meaning of one lexical element, the hyponym, is more specific than the meaning of the other, the hyperonym (e.g., dog—animal).
Lexical items that are hyponyms of the same lexical
element and belong to the same level in the structure are called co-hyponyms (dog, cat, horse are cohyponyms of animal).
Meronymy is when the meaning of one lexical element specifies that its referent is ‘part of’ the referent of another lexical element, for example, hand—body.
2. Roles:
Used to understand situation-specific relations.
Ex: ‘cross a waterbody(oceans, seas, and lakes),’
In semantics, these roles are referred to as semantic roles.
Semantic roles are important for the linking of the arguments to their syntactic realizations.
Ex:
Role Description
agent a willful, purposeful initiator of an event
source the point of origin of a state of affairs
Functional Macro-Categories:
In this section, we present three case studies of fine-grained lexical-semantic analysis.
Formal semantics has had little to say about the meanings of emotion words, but words like these are of great importance to social cognition and communication in ordinary language use.
They may be of special importance to NLP applications connected with social networking and with machine–human interaction, but they differ markedly in their semantics from language to language.
Let us see some contrastive examples.
Consider the difference between sad and unhappy.
I miss you a lot at work . . .. I feel so sad (∗unhappy) about what’s happening to you [said to a colleague in hospital who is dying of cancer].
I was feeling unhappy at work [suggests dissatisfaction].
Semantic explication for Someone X felt sad
a. someone X felt something bad
like someone can feel when they think like this:
b. “I know that something bad happened
I don’t want things like this to happen
I can’t think like this: I will do something because of it now
I know that I can’t do anything”
Also, Semantic explication for Someone X felt unhappy
a. someone X felt something bad
like someone can feel when they think like this:
b. “some bad things happened to me
I wanted things like this not to happen to me
I can’t not think about it”
c. this someone felt something like this, because this someone thought like this
Chapter 6: Natural Language Generation
Natural language generation (NLG) is the process by which thought is rendered into language. It is a software process that automatically transforms data into plain-English or any other natural language content.
It is for the people in the fields of artificial intelligence and computational linguistics.
People have always communicated ideas from data. However, with the explosion of data that needs to be analyzed and interpreted, coupled with increasing pressures to reduce costs and meet customer demands, the enterprise must find innovative ways to keep up.
By the beginning of the 1980s, generation had emerged as a field of its own, with unique concerns and issues, as:
Generation Compared to Comprehension
Computers Are Dumb
The Problem of the Source
Generation Compared to Comprehension
Generation must be seen as a problem of construction and planning, not analysis.
The processing in language comprehension typically follows the traditional stages of a linguistic analysis: phonology, morphology, syntax, semantics, pragmatics; moving gradually from the text to the intentions behind it.
Generation has the opposite information flow. The known is the generator’s awareness of its speaker’s intentions and mood, its plans, and the content and structure of any text the generator has already produced. Coupled with a model of the audience, the situation, and the discourse, this information provides the basis for making choices among the alternative wordings and constructions that the language provides—the primary effort in deliberately constructing a text.
Most generation systems do produce texts sequentially from left to right, but only after having made decisions top-down for the content and form of the text as a whole.
Computers Are Dumb
Two other difficulties with doing research on generation should be cited before moving on. One referred to is the relative stupidity of computer programs, and with it the lack of any practical need for natural language generation as those in the field view it—templates will do just fine.
Computers, on the other hand, do not think very subtle thoughts. The authors of their programs, even artificial intelligence programs, unavoidably leave out the bases and goals behind the instructions for their behavior, and with very few exceptions, computer programs do not have any emotional attitudes toward the people who are using them.
Without the richness of information, perspective, and intention that humans bring to what they say, computers have no basis for making the decisions that go into natural utterances.
The Problem of the Source
In language comprehension the source is obvious; we all know what a written is.
In generation, the source is a ‘state of mind’ inside a speaker with ‘intentions’ acting in a ‘situation’—all terms of art with very slippery meanings. Studying it from a computational perspective, as we are here, we assume that this state of mind has a representation, but there are dozens of formal representations used within the Artificial Intelligence (AI) community that have the necessary expressive power, with no a priori reason to expect one to be better than another as the mental source of an utterance.
The lack of a consistent answer to the question of the generator’s source has been at the heart of the problem of how to make research on generation comprehensible and engaging for the rest of the computational linguistics community.
Relational Issues in Lexical Semantics
Linguistic expressions are interrelated in many ways. Following are the relational issues in lexical semantics:
1 Sense Relations and Ontologies
2 Roles
1. Sense(Semantic) Relations and Ontologies
Ontology is the branch of philosophy that studies concepts such as existence, being and becoming. It includes the questions of how entities are grouped into basic categories and which of these entities exist on the most fundamental level.
Sense relations can be seen as revelatory of the semantic structure of the lexicon.
There are both horizontal and vertical sense relations.
Horizontal relations include synonymy e.g. orange in English is same as Apfelsine in German, incompatible(mismatch) e.g., fin—foot, antonyms e.g. big-small, complementary e.g. aunt—uncle, converse e.g. above-below and reverse e.g. ascend—descend.
The two principal vertical relations are hyponymy and meronymy.
Hyponymy is when the meaning of one lexical element, the hyponym, is more specific than the meaning of the other, the hyperonym (e.g., dog—animal).
Lexical items that are hyponyms of the same lexical
element and belong to the same level in the structure are called co-hyponyms (dog, cat, horse are cohyponyms of animal).
Meronymy is when the meaning of one lexical element specifies that its referent is ‘part of’ the referent of another lexical element, for example, hand—body.
2. Roles:
Used to understand situation-specific relations.
Ex: ‘cross a waterbody(oceans, seas, and lakes),’
In semantics, these roles are referred to as semantic roles.
Semantic roles are important for the linking of the arguments to their syntactic realizations.
Ex:
Role Description
agent a willful, purposeful initiator of an event
source the point of origin of a state of affairs
Functional Macro-Categories:
In this section, we present three case studies of fine-grained lexical-semantic analysis.
Formal semantics has had little to say about the meanings of emotion words, but words like these are of great importance to social cognition and communication in ordinary language use.
They may be of special importance to NLP applications connected with social networking and with machine–human interaction, but they differ markedly in their semantics from language to language.
Let us see some contrastive examples.
Consider the difference between sad and unhappy.
I miss you a lot at work . . .. I feel so sad (∗unhappy) about what’s happening to you [said to a colleague in hospital who is dying of cancer].
I was feeling unhappy at work [suggests dissatisfaction].
Semantic explication for Someone X felt sad
a. someone X felt something bad
like someone can feel when they think like this:
b. “I know that something bad happened
I don’t want things like this to happen
I can’t think like this: I will do something because of it now
I know that I can’t do anything”
Also, Semantic explication for Someone X felt unhappy
a. someone X felt something bad
like someone can feel when they think like this:
b. “some bad things happened to me
I wanted things like this not to happen to me
I can’t not think about it”
c. this someone felt something like this, because this someone thought like this
Chapter 6: Natural Language Generation
Natural language generation (NLG) is the process by which thought is rendered into language. It is a software process that automatically transforms data into plain-English or any other natural language content.
It is for the people in the fields of artificial intelligence and computational linguistics.
People have always communicated ideas from data. However, with the explosion of data that needs to be analyzed and interpreted, coupled with increasing pressures to reduce costs and meet customer demands, the enterprise must find innovative ways to keep up.
By the beginning of the 1980s, generation had emerged as a field of its own, with unique concerns and issues, as:
Generation Compared to Comprehension
Computers Are Dumb
The Problem of the Source
Generation Compared to Comprehension
Generation must be seen as a problem of construction and planning, not analysis.
The processing in language comprehension typically follows the traditional stages of a linguistic analysis: phonology, morphology, syntax, semantics, pragmatics; moving gradually from the text to the intentions behind it.
Generation has the opposite information flow. The known is the generator’s awareness of its speaker’s intentions and mood, its plans, and the content and structure of any text the generator has already produced. Coupled with a model of the audience, the situation, and the discourse, this information provides the basis for making choices among the alternative wordings and constructions that the language provides—the primary effort in deliberately constructing a text.
Most generation systems do produce texts sequentially from left to right, but only after having made decisions top-down for the content and form of the text as a whole.
Computers Are Dumb
Two other difficulties with doing research on generation should be cited before moving on. One referred to is the relative stupidity of computer programs, and with it the lack of any practical need for natural language generation as those in the field view it—templates will do just fine.
Computers, on the other hand, do not think very subtle thoughts. The authors of their programs, even artificial intelligence programs, unavoidably leave out the bases and goals behind the instructions for their behavior, and with very few exceptions, computer programs do not have any emotional attitudes toward the people who are using them.
Without the richness of information, perspective, and intention that humans bring to what they say, computers have no basis for making the decisions that go into natural utterances.
The Problem of the Source
In language comprehension the source is obvious; we all know what a written is.
In generation, the source is a ‘state of mind’ inside a speaker with ‘intentions’ acting in a ‘situation’—all terms of art with very slippery meanings. Studying it from a computational perspective, as we are here, we assume that this state of mind has a representation, but there are dozens of formal representations used within the Artificial Intelligence (AI) community that have the necessary expressive power, with no a priori reason to expect one to be better than another as the mental source of an utterance.
The lack of a consistent answer to the question of the generator’s source has been at the heart of the problem of how to make research on generation comprehensible and engaging for the rest of the computational linguistics community.
Approaches to Text Planning
Text Planning (product details planning) is the process of producing meaningful phrases and sentences in the form of natural language from some internal representation.
It involves −
Text planning − It includes retrieving the relevant content from knowledge base.
Sentence planning − It includes choosing required words, forming meaningful phrases, setting tone of the sentence.
Text Realization − It is mapping sentence plan into sentence structure.
The NLU is harder than NLG.
The techniques for determining the content of the utterance
It is useful in this context to consider a distinction, between ‘macro’ and ‘micro’ planning.
Macro-planning refers to the process that choose the speech, establish the content, determine the situation perspectives, and so on.
Micro-planning is a group of phenomena, determining the detailed organization of the utterance, considering whether to use pronouns, looking at alternative ways to group information into phrases, noting down the focus and information structure that must apply, and other such relatively fine-grained tasks. Also, the lexical choice is crucially important.
Following six approaches are there to Text Planning:
The Function of the Speaker
Desideratum for (Desirable) Text Planning
Pushing vs. Pulling
Planning by Progressive Refinement of the Speaker’s Message
Planning Using Rhetorical Operators
Text Schemas
1. The Function of the Speaker
From the generator’s perspective, the function of the application program for Text Planning in Natural Language Generator is to set the scene.
Text processing defines the situation and the semantic model from which the generator works is so strong that high-quality results can be achieved.
This is the reason why we often speak of the application as the ‘speaker,’ emphasizing the linguistic influences on its design and its tight integration with the generator.
The speaker establishes what content is potentially relevant. It maintains an attitude toward its audience (as a tutor, reference guide, commentator, executive summarizer, copywriter, etc.). It has a history of past transactions. It is the component with the model of the present state and its physical or conceptual context.
In the simplest case, the application consists of just a passive data base of items and plans.
A body of raw data and the job of speaker is to make sense of it in linguistically communicable terms before any significant work can be done by the other components.
When the speaker is a commentator, the situation can evolve from moment to moment in actual real time.
One of the crucial tasks that must often be performed at the juncture between the application and the generator is enriching the information that the application supplies so that it will use the concepts that a person would expect even if the application had not needed them.
2. Desideratum for (Desirable) Text Planning
The tasks of a text planner are many and varied. They include the following:
Construing the speaker’s situation in realizable terms; given the available vocabulary and syntactic resources, an especially important task when the source is raw data (e.g. production description)
Determining the information to include in the utterance and whether it should be stated explicitly or left for inference
Distributing the information into sentences and giving it an organization that reflects the intended rhetorical force, as well as the appropriate conceptual coherence and textual cohesion given the prior discourse
Pushing vs. Pulling
To begin our examination of the major techniques in text planning, we need to consider how the text planner and speaker are connected. The interface between the two is based on one of two logical possibilities: ‘pushing’ or ‘pulling.’
The application can push units of content to the text planner, in effect telling the text planner what to say and leaving it the job of organizing the units into a text with the desired style and rhetorical effect.
Alternatively, the application can be passive, taking no part in the generation process, and the text planner will pull units from it. In this scenario, the speaker is assumed to have no intentions and only the simplest ongoing state (often it is a database). All of the work is then done on the generator’s side of the fence.
Activity
Planning by Progressive Refinement of the Speaker’s Message
This technique—often called ‘direct replacement’—is easy to design and implement, and is the most mature approach.
In its simplest form, it amounts to little more than is done by ordinary database report generators or mail-merge programs when they make substitutions for variables in fixed strings of text.
In its sophisticated forms, which invariably incorporate multiple levels of representation and complex abstractions, it has produced some of the most fluent and flexible texts in the field.
Progressive refinement is a push technique. It starts with a data structure already present in the application and then it gradually transforms that data into a text.
Planning Using Rhetorical Operators
It is a pull technique that operates over a pool (group) of relevant data that has been identified within the application.
The chunks in the pool are typically full planed—the equivalents of single simple items(statements) if they were realized in isolation.
This technique assumes that there is no useful organization to the plans in the pool.
Instead, the mechanisms of the text planner look for matches between the items in the relevant data pool and the planner’s abstract patterns, and select and organize the items accordingly.
Three design elements come together in the practice of operator-based text planning, all of which have their roots in work done in the later 1970s:
The use of formal means-ends analysis techniques
A conception of how communication could be formalized and
Theories of the large-scale ‘grammar’ of discourse structure
Text Schemas
Schemas are the third Text planning techniques and are a pull technique.
They make selections from a pool of relevant data provided by the application according to matches with patterns maintained by the system’s planning knowledge.
The difference is that the choice of operators is fixed rather than actively planned.
Means–ends analysis-based systems assemble a sequence of operators dynamically as the planning is underway.
Given a close fit between the design of the knowledge base and the details of the schema, the resulting texts can be quite good.
Such faults as they have are largely the result of weakness in other parts of the generator and not in its content-selection criteria.
The Linguistic Component
In this section, we look at the core issues in the most mature and well defined of all the processes in natural language generation, the application of a grammar to produce a final text from the elements that were decided upon by the earlier processing.
This is the one area in the whole field where we find true instances of what software engineers would call properly modular components: bodies of code and representations with well-defined interfaces that can be shared between widely varying development groups.
it includes:
Surface Realization Components
Relationship to Linguistic Theory
Chunk Size
Assembling vs. Navigating
Systemic Grammars
Functional Unification Grammars
1. Surface Realization Components
‘Surface’ (output) because what they are charged with doing is producing the final syntactic(grammar) and lexical(word) structure of the text.
The job of a surface realization component is to take the output of the text planner, render it into a form that can be fit in to a grammar, and then apply the grammar to arrive at the final text as a syntactically structured sequence of words, which are read out to become the output of the generator as a whole.
The relationships between the units of the plan are mapped to syntactic relationships. They are organized into compnents and given a linear ordering.
The content words are given grammatically appropriate morphological realizations. Function words (“to,” “of,” “has,” and such) are added as the grammar orders.
2. Relationship to Linguistic Theory
Practically, every modern realization component is an implementation of one of the recognized grammatical formalisms of theoretical linguistics.
The grammatical theories provide systems of rules, sets of principles, systems of constraints, and, especially, a rich set of representations, which, along with a lexicon (not a trivial part in today’s theories), attempt to define the space of possible texts and text fragments in the target natural language.
The designers of the realization components plan ways of interpreting these theoretical constructs and notations into effective machinery for constructing texts that fit in to these systems.
3. Chunk Size
The choice of ‘chunk size’ becomes an architectural necessity, not a freely chosen option.
As implementations of established theories of grammar, realizers must adopt the same scope over linguistic properties as their parent theories do; anything larger or smaller would be undefined.
Given a set of plans to be communicated, the designer of a planner working in this paradigm is more likely to think in terms of a succession of sentences rather than trying to interleave one plan within the realization of another.
Such lockstep treatments can be especially confining when higher order plans are to be communicated.
For example, the natural realization of such a plan might be adding “only” inside the sentence that realizes its argument, yet the full-sentence-at-a-time paradigm makes this exceedingly difficult to appreciate as a possibility let alone carry out.
4. Assembling vs. Navigating
Grammars, and with them the processing architectures of their realization components, fall into two camps.
The grammar provides a set of relatively small structural elements and constraints on their combination.
The grammar is a single complex network or descriptive device that defines all the possible output texts in a single abstract structure.
When the grammar consists of a set of combination of elements, the task of the realization component is to select from this set and assemble them into a composite representation from which the text is then read out.
When the grammar is a single structure, the task is to navigate through the structure, accumulating and refining the basis for the final text along the way and producing it all at once when the process has finished.
5. Systemic Grammars
Understanding and representing the context into which the elements of an utterance are fit and the role of the context in their selection is a central part of the development of a grammar.
It is especially important when the perspective that the grammarian takes is a functional(purpose) rather than a structural one(content)—the viewpoint adopted in Systemic Grammar.
A systemic grammar is written as a specialized kind of decision tree: ‘If this choice is made, then this set of alternatives becomes relevant; if a different choice is made, those alternatives can be ignored, but this other set must now be addressed.
6. Functional Unification Grammars
What sets functional approaches to realization apart from structural approaches is the choice of terminology and distinctions, the indirect relationship to syntactic surface structure, and, when embedded in a realization component, the nature of its interface to the earlier text-planning components.
Functional realizers are concerned with purposes, not contents.
The Cutting Edge
There has been a great deal of technical development in the last decade.
There are two systems that are breaking entirely new ground:
Story Generation and
Personality-Sensitive Generation
Story Generation
Story Generation consists of two main components:
(i) the NLP component and (ii) the graphics component.
The user enters a story in the tool one sentence at a time. When a sentence has been completed, the NLP component analyzes it. Based on its analysis, the component passes on information that the graphics component will need to generate an appropriate animated graphic in 3D space.
In this prototype, the NLP output includes information on the actor, action, object, background, etc. in the input sentence. For instance, Figure 1 is the output from the NLP component for the sentence, “the man kicked a ball on the beach.”
Personality-Sensitive Generation
Remarkably few generation systems have been developed where the speaker could be said to have a particular personality.
First of all, there must be a large number of relevant ‘units’ of content that could be included or ignored or systematically left to inference according to the desired level detail or choice of perspective.
Second and more important is the use of a multilevel ‘standoff’ architecture whereby pragmatic (logical) concepts are progressively reinterpreted through one or more level of description as features that a generator can actually attend to (e.g., word choice, sentence length, clause complexity).

Unit -3
POS tagging: Introduction, The General Framework, Part-of-Speech Tagging Approaches : Rule based approaches, stochastic approach, Markov Model approaches, Maximum Entropy Approaches, Other Statistical and Machine Learning Approaches - Methods and Relevant Work, Combining TaggersPOS Tagging in Languages Other Than English - Chinese and Korean.Evaluation Metrics for Machine Learning - Accuracy, Precision, Recall
10.1 Introduction
Part-of-Speech (POS) tagging is normally a sentence-based approach and given a sentence formed of a sequence of words, POS tagging tries to label (tag) each word with its correct part of speech (also named word category, word class, or lexical category).
POS tagging only deals with assigning a POS tag to the given form word. This is more true for IndoEuropean languages, which are the mostly studied languages in the literature.
Other languages may require a more sophisticated analysis for POS tagging due to their complex morphological structures.
Parts of Speech
POS is a kind of lexical(word) categorization.
There are three major (primary) parts of speech: noun, verb, and adjective.
Also, linguistic models propose some additional categories such as (adposition (Prepositions and postpositions), determiner, etc.).
Usually the size of the tagset is large and there is a rich collection of tags with high discriminative power.
The most frequently used corpora (for English) in the POS tagging research and the corresponding tagsets are as follows:
- Brown corpus (87 basic tags and special indicator tags),
- Lancaster-Oslo/Bergen (LOB) corpus (135 tags of which 23 are base tags),
- Penn Treebank and Wall Street Journal (WSJ) corpus (48 tags of which 12 are for punctuation and other symbols), and
- Susanne corpus (353 tags).




10.4 Other Statistical and Machine Learning Approaches



















11.5 Discriminative Models






11.10 MaltParser




Learning and Parsing



12.2.1.5 Statistical Idiomaticity

In Table 12.2, kick the bucket (in the sense of “die”) has only one form of idiomaticity (semantic), while all the other examples have at least two forms of idiomaticity.
Nominal MWEs
Verbal MWEsPrepositional MWEs
Association MeasuresAttributesRelational Word SimilarityLatent Semantic AnalysisAssociation Measures


NLP - Question
bank
Unit 1
1. What is NLP? Explain any five applications of NLP.
2. Explain the Challenges that can be faced while designing
NLP software.
3. Describe NLP abstraction levels in short.
4. What are various Characteristics of Natural Language?
Explain in detail.
5. Describe various NL computing techniques and steps in
detail.
6. What are various ways to create segmentation of written
text into meaningful units?
7. Write a short note on one of the natural language tasks –
Tagging.
8. What is chunking in NLP? What are the Rules for Chunking?
9. Write a short note on Named Entity Recognition.
10. Describe text parsing in NLP.
11. What Types of ambiguity available in NLP? Describe
various Approaches and
Methods to Word Sense Disambiguation.
12. How NL Generation works? Explain in detail.
13. Define Sentiment Analysis. Explain its classification
levels.
14. Explain Text Entailment with examples.
15. Write a brief note on Cross Lingual Information
Retrieval.
16. How Space-Delimited Languages tokenize a word? Describe
in brief.
17. What are common approaches to tokenize a word in
Unsegmented Languages?
How is word segmentation done in Chinese and Japanese
languages
18. How Sentences can be delimited in most written
languages? Write about
Sentence Boundary Punctuation.
19. How Sentences can be delimited in most written
languages? Write about the
importance of Context.
20. How Sentences can be delimited in most written
languages? Write about the
Traditional Rule-Based Approaches.
21. How Sentences can be delimited in most written
languages? Write about the
Robustness and Trainability.
22. What is lexical analysis? Explain in brief. Also explain
Finite state Automaton
with its network.
23. What is lexical analysis? Also explain how Finite State
Automaton (FSA)
converts Noun from Singular to Plural.
24. Write a brief note on Lexicon in Finite State Automaton
(FSA).
25. What is lexical analysis? how Finite State Transducers
Converts plural to
singular (lemma).
26. Describe Two level morphology in detail.
27. Write a brief note on Finite State Morphology.
28. Explain “Difficult” Morphology and Lexical Analysis.
Unit 2
1. What is Syntactic parsing? What are the difficulties in
creating Syntactic parsing?
2. How syntactic parsing can be done using Context Free
Grammar? Explain with example.
3. Describe various syntactic parsing techniques.
4. What are the Basic Concepts in Parsing?
5. Build the syntactic parsing tree using the following
sentence and the grammar given. Apply top down and bottom up approaches.
I/P :- Book that flight
S -> VP
VP -> VP NP
NP -> Det NP
Det -> that
NP -> singular Noun
singular Noun -> flight
Verb -> book
6. How to Implement Deductive Parsing? Explain with respect
to Agenda-Driven Chart Parsing.
7. How to Implement Deductive Parsing? Explain with respect
to Storing and Retrieving Parse Results.
8. Explain in detail about LR syntactic Parsing.
9. What are the Issues in Parsing? Explain in detail.
10. What are the Basic Concepts and Issues in Natural
Language Semantics? Explain in detail.
11. Explain Logical Approaches to Semantic Representation in
detail.
12. Explain Discourse Representation Theory approach to Semantic Representation in
detail.
13. Explain Pustejovsky’s Generative Lexicon approach to
Semantic Representation in detail.
14. Explain Natural Semantic Metalanguage approach to
Semantic Representation in detail.
15. What are various Theories and Approaches to Semantic
Representation? Explain Object-Oriented Semantics approach to Semantic
Representation in detail.
16. Write a short note on Relational Issues in Lexical
Semantics.
17. Explain Functional Macro-Categories with respect to
fine-grained lexical-semantic analysis.
18. What is Natural language generation? How generation can
be compared with comprehension?
19. What is Natural language generation? What are the issues
in it?
20. What are the components of a natural language generator?
Explain each one in short.
21. Explain The Function of the Speaker approach to Text
Planning in natural language generation.
22. Explain Desideratum for Text Planning and Pushing vs.
Pulling approach in natural language generation.
23. What are various approaches to Text Planning in natural
language generation? Explain Planning by Progressive Refinement of the Speaker’s
Message in detail.
24. Explain Planning Using Rhetorical Operators approach to
Text Planning in natural language generation.
25. Explain Text Schemas approach to Text Planning in
natural language generation.
26. What are the Linguistic Components in Natural Language
generation? Explain each one in short.
Unit 3
1.
What are the common problems with part of speech
tagging systems? Describe In detail.
2.
Describe the General Framework of part of speech
tagging.
3.
How rule-based approaches work in part of speech
tagging? Also write about its two-stage architecture and properties.
4.
Which approaches are applied by the simplest
stochastic tagger? Also, write about Properties of Stochastic POS Tagging.
5.
What is transformation-based learning? Also,
explain the working of Transformation Based Learning.
6.
What is transformation-based learning? Write its
advantages and disadvantages.
7.
What is transformation-based learning? what are
the Modifications to TBL and Other Rule-Based Approaches?
8.
What is Hidden Markov Model? Also, explain the use
of HMM for Part of Speech Tagging.
9.
What are the drawbacks of Hidden Markow Model?
How Maximum Entropy Models overcome the drawbacks of HMM?
10.
What is confusion matrix? What are its four
basic terminologies? Also write the definition and formula of accuracy,
precision and recall.
Unit 4
1.
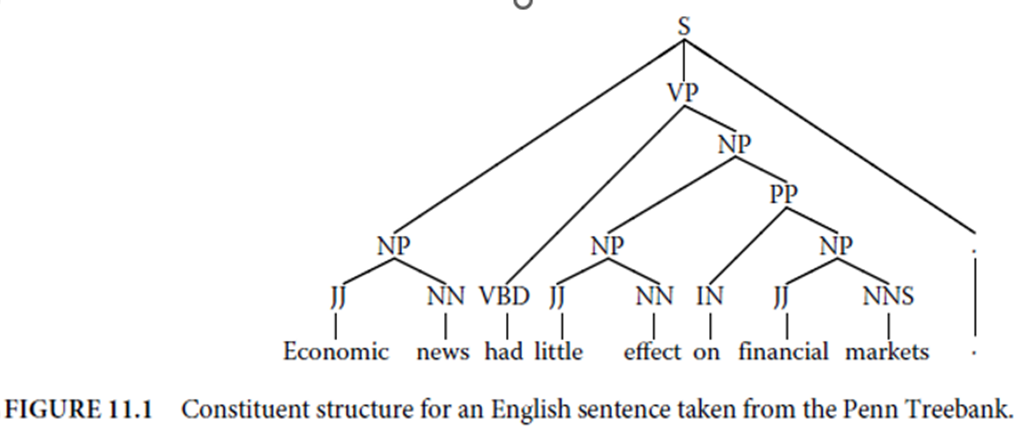
Explain constituent structure and dependency
structure for an English sentence with a neat diagram with respect to Syntactic
Representations of Statistical Parsing.
2.
Write in brief about Statistical Parsing Models.
Also, explain Parser Evaluation in Statistical Parsing.
3.
How PCFGs work as Statistical Parsing Models?
Explain with a neat diagram.
4.
Describe Generative Models. Also compare it with
PCFG model.
5.
Describe History-Based Models in detail.
6.
Write a brief note on PCFG Transformations.
7.
Describe the standard version of Data-Oriented
Parsing in detail.
8.
Explain the working of Local Discriminative
Models in detail.
9.
Explain the working of Global Discriminative
Models in detail.
10.
Explain in brief about Beyond Supervised Parsing,
Weakly Supervised Parsing and unsupervised parsing.
11.
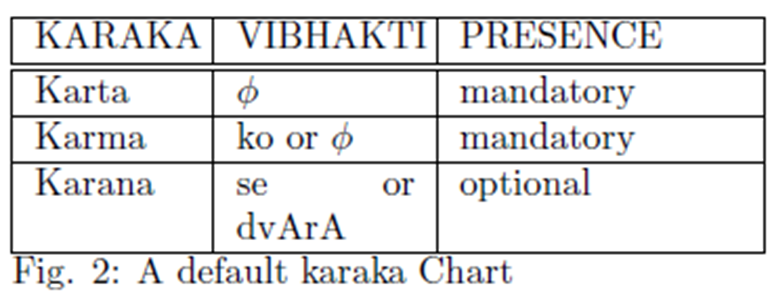
What is Indian Language Parsing in Paninian
Karaka Theory? Explain with respect to a default karaka chart and
transformation rules.
12.
What is constraint-based parsing? Explain in
detail with respect to Paninian Karaka Theory.
13.
What is malt-parsing? Explain in brief with
respect to Inductive Dependency Parsing.
14.
Write a brief note on Parsing Algorithms of malt
parsing.
15.
Explain Feature Models in brief with respect to
malt parsing.
16.
What is Learning Algorithms in malt parsing?
Also write about Learning and Parsing.
Unit 5
1.
What is MWEs? Explain Linguistic Properties of
MWEs Idiomaticity property of its in detail.
2.
Describe Lexical Idiomaticity and statistic Idiomaticity
of MWEs.
3.
Describe Syntactic Idiomaticity and Semantic
Idiomaticity of MWEs.
4.
Describe Lexical Idiomaticity and Pragmatic Idiomaticity
of MWEs.
5.
How to Test an Expression for MWEhood? Explain
in detail.
6.
What are the Types of MWEs? Explain Verbal MWEs
in detail.
7.
What are the Types of MWEs? Explain Nominal MWEs
and Prepositional MWEs in detail.
8.
Why do we use normalized web distance? Explain
any two methods of it.
9.
Explain Association Measures and Attributes methods
for Word Similarity.
10.
Describe Relational Word Similarity and Latent
Semantic Analysis methods for Word Similarity.
11.
What is Kolmogorov Complexity? Explain in brief.
12.
Define Information Distance. Also explain Normalized
Information Distance.
13.
Define Information Distance. Also explain Normalized
Compression Distance.
14.
Write a brief note on Applications and
Experiments of Normalized word
NLP
Lab Manual
https://medium.com/nerd-for-tech/text-summarization-with-machine-and-deep-learning-in-python-4fbaf5cf746b
Practical No. 1:
a)
Install NLTK
Python
3.9.2 Installation on Windows
Step 1) Go
to link https://www.python.org/downloads/, and
select the latest version for windows.
Note: If you don't want to download the latest version, you
can visit the download tab and see all releases.
Step 2) Click on the Windows installer (64 bit)
Step 3) Select Customize Installation
Step 4) Click NEXT
Step 5) In next screen
1.
Select the advanced options
2.
Give a Custom install location. Keep the default folder as c:\Program
files\Python39
3.
Click Install
Step 6) Click Close button once install is done.
Step 7) open command
prompt window and run the following commands:
C:\Users\Beena
Kapadia>pip install --upgrade pip
C:\Users\Beena
Kapadia> pip install --user -U nltk
C:\Users\Beena
Kapadia> >pip install --user -U numpy
C:\Users\Beena
Kapadia>python
>>> import
nltk
>>>
(Browse
https://www.nltk.org/install.html for more details)
b)
Convert the given text to speech.
Source
code:
#
text to speech
#
pip install gtts
#
pip install playsound
from
playsound import playsound
#
import required for text to speech conversion
from
gtts import gTTS
mytext
= "Welcome to Natural Language programming"
language
= "en"
myobj
= gTTS(text=mytext, lang=language, slow=False)
myobj.save("myfile.mp3")
playsound("myfile.mp3")
Output:
welcomeNLP.mp3
audio file is getting created and it plays the file with playsound() method,
while running the program.
c)
Convert audio file Speech to Text.
Source
code:
Note:
required to store the input file "male.wav" in the current folder
before running the program.
#pip3
install SpeechRecognition pydub
import
speech_recognition as sr
filename
= " the most
frequent noun "
#
initialize the recognizer
r
= sr.Recognizer()
#
open the file
with
sr.AudioFile(filename) as source:
# listen for the data (load audio to
memory)
audio_data = r.record(source)
# recognize (convert from speech to text)
text = r.recognize_google(audio_data)
print(text)
Input:
male.wav
(any wav file)
Output:
Practical No. 2:
a.
Study of various Corpus – Brown, Inaugural, Reuters, udhr with various methods
like filelds, raw, words, sents, categories.
b.
Create and use your own corpora (plaintext, categorical)
c.
Study of tagged corpora with methods like tagged_sents, tagged_words.
d.
Write a program to find the most frequent noun tags.
2 a. Study of
various Corpus – Brown, Inaugural, Reuters, udhr with various methods like
fields, raw, words, sents, categories,
source
code:
'''NLTK includes a
small selection of texts from the Project brown electronic text archive, which
contains some 25,000 free electronic books, hosted at http://www.brown.org/. We
begin by getting the Python interpreter to load the NLTK package, then ask to see
nltk.corpus.brown.fileids(), the file identifiers in this corpus:'''
import
nltk
from
nltk.corpus import brown
print
('File ids of brown corpus\n',brown.fileids())
'''Let’s pick out the first of these texts
— Emma by Jane Austen — and give it a short name, emma, then find out how many
words it contains:'''
ca01
= brown.words('ca01')
#
display first few words
print('\nca01
has following words:\n',ca01)
#
total number of words in ca01
print('\nca01
has',len(ca01),'words')
#categories
or files
print
('\n\nCategories or file in brown corpus:\n')
print
(brown.categories())
'''display other
information about each text, by looping over all the values of fileid corresponding
to the brown file identifiers listed earlier and then computing statistics for
each text.'''
print
('\n\nStatistics for each text:\n')
print
('AvgWordLen\tAvgSentenceLen\tno.ofTimesEachWordAppearsOnAvg\t\tFileName')
for
fileid in brown.fileids():
num_chars = len(brown.raw(fileid))
num_words = len(brown.words(fileid))
num_sents = len(brown.sents(fileid))
num_vocab = len(set([w.lower() for w in
brown.words(fileid)]))
print (int(num_chars/num_words),'\t\t\t',
int(num_words/num_sents),'\t\t\t', int(num_words/num_vocab),'\t\t\t', fileid)
output:
b. Create and use your own corpora (plaintext,
categorical)
source
code:
'''NLTK includes a small selection of
texts from the Project filelist electronic text archive, which contains some
25,000 free electronic books, hosted at http://www.filelist.org/. We begin by
getting the Python interpreter to load the NLTK package, then ask to see
nltk.corpus.filelist.fileids(), the file identifiers in this corpus:'''
import
nltk
from
nltk.corpus import PlaintextCorpusReader
corpus_root
= 'D:/2020/NLP/Practical/uni'
filelist
= PlaintextCorpusReader(corpus_root, '.*')
print
('\n File list: \n')
print
(filelist.fileids())
print
(filelist.root)
'''display other information about each
text, by looping over all the values of fileid corresponding to the filelist
file identifiers listed earlier and then computing statistics for each text.'''
print
('\n\nStatistics for each text:\n')
print
('AvgWordLen\tAvgSentenceLen\tno.ofTimesEachWordAppearsOnAvg\tFileName')
for
fileid in filelist.fileids():
num_chars = len(filelist.raw(fileid))
num_words = len(filelist.words(fileid))
num_sents = len(filelist.sents(fileid))
num_vocab = len(set([w.lower() for w in
filelist.words(fileid)]))
print (int(num_chars/num_words),'\t\t\t',
int(num_words/num_sents),'\t\t\t', int(num_words/num_vocab),'\t\t', fileid)
output:
c.
Study of tagged corpora with methods like tagged_sents, tagged_words.
Source
code:
import
nltk
from
nltk import tokenize
nltk.download('punkt')
nltk.download('words')
para
= "Hello! My name is Beena Kapadia. Today you'll be learning NLTK."
sents
= tokenize.sent_tokenize(para)
print("\nsentence
tokenization\n===================\n",sents)
#
word tokenization
print("\nword
tokenization\n===================\n")
for
index in range(len(sents)):
words = tokenize.word_tokenize(sents[index])
print(words)
output:
d.
Write a program to find the most frequent noun tags.
Code:
import
nltk
from
collections import defaultdict
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
text
= nltk.word_tokenize("Nick likes to play football. Nick does not like to
play cricket.")
tagged
= nltk.pos_tag(text)
print(tagged)
#
checking if it is a noun or not
addNounWords
= []
count=0
for
words in tagged:
val = tagged[count][1]
if(val == 'NN' or val == 'NNS' or val ==
'NNPS' or val == 'NNP'):
addNounWords.append(tagged[count][0])
count+=1
print
(addNounWords)
temp
= defaultdict(int)
#
memoizing count
for
sub in addNounWords:
for wrd in sub.split():
temp[wrd] += 1
#
getting max frequency
res
= max(temp, key=temp.get)
#
printing result
print("Word
with maximum frequency : " + str(res))
output:
3. a. Study of
Wordnet Dictionary with methods as synsets, definitions, examples, antonyms
‘‘‘ WordNet is the lexical database i.e.
dictionary for the English language, specifically designed for natural language
processing.
Synset is
a special kind of a simple interface that is present in NLTK to look up words
in WordNet. Synset instances are the groupings of synonymous words that express
the same concept. Some of the words have only one Synset and some have
several.’’’
Source code:
'''WordNet
provides synsets which is the collection of synonym words also called
“lemmas”'''
import nltk
from nltk.corpus
import wordnet
nltk.download('wordnet')
print(wordnet.synsets("computer"))
# definition and
example of the word ‘computer’
print(wordnet.synset("computer.n.01").definition())
#examples
print("Examples:",
wordnet.synset("computer.n.01").examples())
#get Antonyms
print(wordnet.lemma('buy.v.01.buy').antonyms())
output:
b. Study lemmas,
hyponyms, hypernyms.
Hyponyms
and hypernyms are both terms that come under the lexis/semantics section of
English language. A hypernym describes a more broad term, for example color. A
hyponym is a more specialised and specific word, for example: Purple, Red,
Blue, Green would be a hyponym of color.
Source code:
import nltk
from nltk.corpus
import wordnet
nltk.download('wordnet')
print(wordnet.synsets("computer"))
print(wordnet.synset("computer.n.01").lemma_names())
#all lemmas for
each synset.
for e in wordnet.synsets("computer"):
print(f'{e} --> {e.lemma_names()}')
#print all lemmas
for a given synset
print(wordnet.synset('computer.n.01').lemmas())
#get the synset
corresponding to lemma
print(wordnet.lemma('computer.n.01.computing_device').synset())
#Get the name of
the lemma
print(wordnet.lemma('computer.n.01.computing_device').name())
#Hyponyms give
abstract concepts of the word that are much more specific
#the list of
hyponyms words of the computer
syn =
wordnet.synset('computer.n.01')
print(syn.hyponyms)
print([lemma.name()
for synset in syn.hyponyms() for lemma in synset.lemmas()])
#the semantic
similarity in WordNet
vehicle =
wordnet.synset('vehicle.n.01')
car =
wordnet.synset('car.n.01')
print(car.lowest_common_hypernyms(vehicle))
Output:
c)
sentence tokenization, word tokenization, Part of speech Tagging and chunking
of user defined text.
Source
code:
import
nltk
from
nltk import tokenize
nltk.download('punkt')
from
nltk import tag
from
nltk import chunk
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')
nltk.download('words')
para
= "Hello! My name is Beena Kapadia. Today you'll be learning NLTK."
sents
= tokenize.sent_tokenize(para)
print("\nsentence
tokenization\n===================\n",sents)
#
word tokenization
print("\nword
tokenization\n===================\n")
for
index in range(len(sents)):
words = tokenize.word_tokenize(sents[index])
print(words)
#
POS Tagging
tagged_words
= []
for
index in range(len(sents)):
tagged_words.append(tag.pos_tag(words))
print("\nPOS
Tagging\n===========\n",tagged_words)
#
chunking
tree
= []
for
index in range(len(sents)):
tree.append(chunk.ne_chunk(tagged_words[index]))
print("\nchunking\n========\n")
print(tree)
Output:
sentence
tokenization
===================
['Hello!', 'My name is Beena Kapadia.',
"Today you'll be learning NLTK."]
word
tokenization
===================
['Hello',
'!']
['My',
'name', 'is', 'Beena', 'Kapadia', '.']
['Today',
'you', "'ll", 'be', 'learning', 'NLTK', '.']
POS
Tagging
===========
[[('Today', 'NN'), ('you', 'PRP'),
("'ll", 'MD'), ('be', 'VB'), ('learning', 'VBG'), ('NLTK', 'NNP'),
('.', '.')], [('Today', 'NN'), ('you', 'PRP'), ("'ll", 'MD'), ('be',
'VB'), ('learning', 'VBG'), ('NLTK', 'NNP'), ('.', '.')], [('Today', 'NN'),
('you', 'PRP'), ("'ll", 'MD'), ('be', 'VB'), ('learning', 'VBG'),
('NLTK', 'NNP'), ('.', '.')]]
chunking
========
[Tree('S',
[('Today', 'NN'), ('you', 'PRP'), ("'ll", 'MD'), ('be', 'VB'),
('learning', 'VBG'), Tree('ORGANIZATION', [('NLTK', 'NNP')]), ('.', '.')]),
Tree('S', [('Today', 'NN'), ('you', 'PRP'), ("'ll", 'MD'), ('be',
'VB'), ('learning', 'VBG'), Tree('ORGANIZATION', [('NLTK', 'NNP')]), ('.',
'.')]), Tree('S', [('Today', 'NN'), ('you', 'PRP'), ("'ll", 'MD'),
('be', 'VB'), ('learning', 'VBG'), Tree('ORGANIZATION', [('NLTK', 'NNP')]),
('.', '.')])]
4. a)
Named Entity recognition using user defined text.
Source
code:
!pip
install -U spacy
!python
-m spacy download en_core_web_sm
import
spacy
#
Load English tokenizer, tagger, parser and NER
nlp
= spacy.load("en_core_web_sm")
#
Process whole documents
text
= ("When Sebastian Thrun started working on self-driving cars at "
"Google in 2007, few people
outside of the company took him "
"seriously. “I can tell you very
senior CEOs of major American "
"car companies would shake my hand
and turn away because I wasn’t "
"worth talking to,” said Thrun, in
an interview with Recode earlier "
"this week.")
doc
= nlp(text)
#
Analyse syntax
print("Noun
phrases:", [chunk.text for chunk in doc.noun_chunks])
print("Verbs:",
[token.lemma_ for token in doc if token.pos_ == "VERB"])
Output:
Noun
phrases: ['Sebastian Thrun', 'self-driving cars', 'Google', 'few people', 'the
company', 'him', 'I', 'you', 'very senior CEOs', 'major American car
companies', 'my hand', 'I', 'Thrun', 'an interview', 'Recode']
Verbs:
['start', 'work', 'drive', 'take', 'tell', 'shake', 'turn', 'be', 'talk',
'say']
b)
Named Entity recognition with diagram using NLTK corpus – treebank.
Source
code:
Note:
It runs on Python IDLE
import
nltk
nltk.download('treebank')
from
nltk.corpus import treebank_chunk
treebank_chunk.tagged_sents()[0]
treebank_chunk.chunked_sents()[0]
treebank_chunk.chunked_sents()[0].draw()
Output:
5. a) Implementation of Deductive Chart Parsing
using context free grammar and a given sentence – Book that flight
Source
code:
import nltk
from nltk import tokenize
grammar1 =
nltk.CFG.fromstring("""
S
-> VP
VP -> VP NP
NP -> Det NP
Det -> 'that'
NP -> singular Noun
NP -> 'flight'
VP -> 'Book'
""")
sentence = "Book that flight"
nltk.download('punkt')
for index in range(len(sentence)):
all_tokens = tokenize.word_tokenize(sentence)
print(all_tokens)
parser = nltk.ChartParser(grammar1)
for tree in parser.parse(all_tokens):
print(tree)
tree.draw()
output:
Source
code:
import
nltk
from
nltk import tokenize
grammar1
= nltk.CFG.fromstring("""
S
-> NP VP
PP
-> P NP
NP
-> Det N | Det N PP | 'I'
VP
-> V NP | VP PP
Det
-> 'a' | 'my'
N
-> 'bird' | 'balcony'
V
-> 'saw'
P
-> 'in'
""")
sentence
= "I saw a bird in my balcony"
for
index in range(len(sentence)):
all_tokens = tokenize.word_tokenize(sentence)
print(all_tokens)
#
all_tokens = ['I', 'saw', 'a', 'bird', 'in', 'my', 'balcony']
parser
= nltk.ChartParser(grammar1)
for
tree in parser.parse(all_tokens):
print(tree)
tree.draw()
output:
6. a) Analyzing the meaning of sentence
by querying a database. Find the cities of India by applying a query - 'What
cities are located in India' and the context free grammar from the file
'sqlIndia.fcfg'. Hint: sqlIndia.fcfg file should be in the same folder.
Source code:
#Analysing the meaning of sentence by
querying a database
# show CFG
# pip install nltk
import nltk
nltk.data.show_cfg('sqlIndia.fcfg')
# Convert into bracket (list] form
from nltk.parse import load_parser
cp = load_parser('sqlIndia.fcfg')
query = 'What
cities are located in India'
trees = list(cp.parse(query.split()))
print (trees)
# generate query as a sentence with
punctuations (,)
answer = trees[0].label()['SEM']
print (answer)
# generate query as tokens
answer = [s for s in answer if s]
#join all tokens
q = ' '.join(answer)
print (q)
## TILL NOW WE HAVE CONVERTED NLP STAEMENT
INTO DATABASE STATEMENT ##
# Finally, we execute the query over the
database city.db and retrieve some results:
from nltk.sem import chat80
nltk.download('city_database')
# apply query q to city.db
rows =
chat80.sql_query('corpora/city_database/city.db', q)
# print cities
for r in rows:
print (r)
output:
b. # Building a Discourse Representation
Theory(DRT) by parsing a string representation - Angus
owns a dog.
Source code:
# e.g.'Angus owns a dog'.
# A discourse representation structure
(DRS) presents the meaning of discourse.
# parse a string and represent Discourse
Representation Structure
import nltk
read_the_expr =
nltk.sem.DrtExpression.fromstring
drs1 = read_the_expr('([x, y], [Angus(x),
dog(y), own(x, y)])')
print(drs1)
drs1.draw()
# every DRS can be translated into a
formula of first-order logic, and the fol() method implements this translation.
print(drs1.fol())
# In order to parse with grammar drt.fcfg,
we specify in the call to load_parser() that SEM values in feature structures
are to be parsed using DrtParser.
from nltk import load_parser
parser =
load_parser('grammars/book_grammars/drt.fcfg',
logic_parser=nltk.sem.drt.DrtParser())
trees = list(parser.parse('Angus owns a
dog'.split()))
print(trees[0].label()['SEM'].simplify())
trees[0].draw()
output:
7. Study
PorterStemmer, LancasterStemmer, RegexpStemmer, SnowballStemmer
and WordNetLemmatizer
Code:
#
PorterStemmer
import
nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
print(word_stemmer.stem('writing'))
Output:
import
nltk
from
nltk.stem import LancasterStemmer
Lanc_stemmer
= LancasterStemmer()
print(Lanc_stemmer.stem('writing'))
Output:
#RegexpStemmer
import
nltk
from
nltk.stem import RegexpStemmer
Reg_stemmer
= RegexpStemmer('ing$|s$|e$|able$', min=4)
print(Reg_stemmer.stem('writing'))
output
#SnowballStemmer
import
nltk
from
nltk.stem import SnowballStemmer
english_stemmer
= SnowballStemmer('english')
print(english_stemmer.stem
('writing'))
output
#WordNetLemmatizer
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print("word :\tlemma")
print("rocks :", lemmatizer.lemmatize("rocks"))
print("corpora :", lemmatizer.lemmatize("corpora"))
# a denotes adjective in "pos"
print("better :", lemmatizer.lemmatize("better",
pos ="a"))
Output:
8 a) Parse a
sentence - "old men and women" and draw a tree using probabilistic
parser
Source code:
import nltk
from nltk import
PCFG
grammar =
PCFG.fromstring('''
NP -> NNS [0.5]
| JJ NNS [0.3] | NP CC NP [0.2]
NNS ->
"men" [0.1] | "women" [0.2] | "children" [0.3] |
NNS CC NNS [0.4]
JJ ->
"old" [0.4] | "young" [0.6]
CC ->
"and" [0.9] | "or" [0.1]
''')
print(grammar)
viterbi_parser =
nltk.ViterbiParser(grammar)
token = "old men and women".split()
obj =
viterbi_parser.parse(token)
print("Output:
")
for x in obj:
print(x)
Output:
b). Malt parsing:
Parse a sentence -
'I saw a bird from my window.' and draw a tree using malt parsing.
Note: 1) Java should be installed.
2)
maltparser-1.7.2 zip file should be copied in C:\Users\Beena
Kapadia\AppData\Local\Programs\Python\Python39 folder and should be
extracted in the same folder.
3)
engmalt.linear-1.7.mco file should be copied to C:\Users\Beena
Kapadia\AppData\Local\Programs\Python\Python39 folder
Source code:
# copy
maltparser-1.7.2(unzipped version) and engmalt.linear-1.7.mco files to
C:\Users\Beena Kapadia\AppData\Local\Programs\Python\Python39 folder
# java should be
installed
# environment
variables should be set - MALT_PARSER - C:\Users\Beena
Kapadia\AppData\Local\Programs\Python\Python39\maltparser-1.7.2 and MALT_MODEL
- C:\Users\Beena Kapadia\AppData\Local\Programs\Python\Python39\engmalt.linear-1.7.mco
from nltk.parse
import malt
mp = malt.MaltParser('maltparser-1.7.2',
'engmalt.linear-1.7.mco')#file
t = mp.parse_one('I saw a bird
from my window.'.split()).tree()
print(t)
t.draw()
Output:
(saw I (bird a
(from (window. my))))
Source code:
# Multiword Expressions in NLP
from nltk.tokenize import MWETokenizer
from nltk import sent_tokenize,
word_tokenize
s = '''Good cake
cost Rs.1500\kg in New Delhi. Please buy
me one of them.\n\nThanks.'''
mwe =
MWETokenizer([('New', 'Delhi'), ('New', 'York'), ('Hong', 'Kong')],
separator='_')
for sent in sent_tokenize(s):
print(mwe.tokenize(word_tokenize(sent)))
Output:
Source
code:
#Pr
9 b WSD
#The
purpose of WSD is to accurately understand the meaning of a word in particular
usage or sentence, it can be used for the correct labeling of words.
from
nltk.wsd import lesk
from
nltk.tokenize import word_tokenize
import
nltk
nltk.download('punkt')
nltk.download('wordnet')
a1=
lesk(word_tokenize('This device is used to jam the signal'),'jam')
print(a1,a1.definition())
a2
= lesk(word_tokenize('I am stuck in a traffic jam'),'jam')
print(a2,a2.definition())
b1=lesk(word_tokenize('I
love reading books on coding.'),'book')
print(b1,b1.definition())
b2
= lesk(word_tokenize('The table was already booked by someone else.'),'book')
print(b2,b2.definition())
Output:
Comments
Post a Comment